The Pipeline
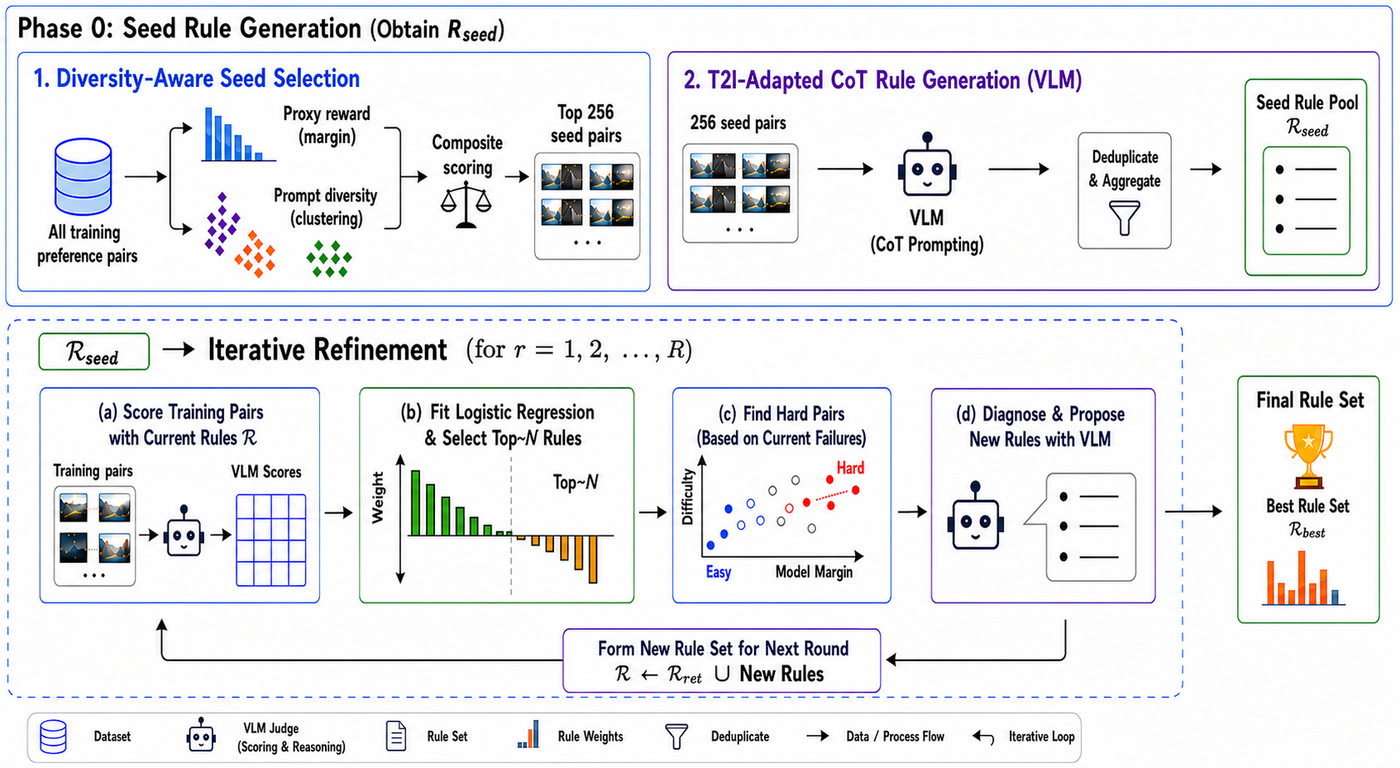
AutoRubric-T2I operates in two phases: seed rule generation from a small set of preference pairs, followed by iterative refinement that discovers and retains the most predictive rubrics through sparse weighting and hard-pair mining.
Phase 0
Seed Rule Generation
(obtain Rseed)
1. Diversity-Aware Seed Selection
All Training Pairs
Full preference dataset
Composite Scoring
Proxy reward × prompt diversity
Top 256 Seed Pairs
High-margin, diverse seeds
2. T2I-Adapted CoT Rule Generation
256 Seed Pairs
Selected preference pairs
VLM Judge
CoT prompting per pair
Deduplicate & Aggregate
Merge similar rules
Rseed
Initial seed rule pool
Iterative
Refinement
(for r = 1, 2, …, R)
a
Score Training Pairs
VLM scores pairs with current rules ℝ
b
ℓ₁ Regression
Fit logistic regression, select top-N rules
c
Find Hard Pairs
Mine failures by difficulty & margin
d
Propose New Rules
VLM diagnoses hard cases, drafts rules
Form new rule set: ℝ ← ℝret ∪ New Rules
🏆
Best Rule Set Rbest
Compact, weighted natural-language rubrics
Process
node
Output
node
Iterative
step
Data flow
Iterative loop
Show the static pipeline figure from the paper